The Missing Layer: Lifecycle Management¶
What Lifecycle Management Actually Means¶
The term “lifecycle management” is widely used.
It appears in discussions about device management, firmware updates, and IoT platforms. It is often associated with over-the-air updates, version control, or basic monitoring capabilities.
At a glance, it seems familiar. In the context of Edge AI, this familiarity can be misleading. Lifecycle management is not a single capability.
It is not a feature that can be added to an existing system. It is the system responsible for controlling what happens to a device over time. Without control over time, there is no real control at all — this distinction matters.
Updating firmware is part of lifecycle management. Monitoring device behavior is part of lifecycle management. Managing identity, trust, and communication is part of lifecycle management — none of these, on their own, define it.
Lifecycle management exists across the entire lifespan of a device — from the moment it is provisioned, through deployment and operation, to updates, maintenance, and eventual decommissioning.
It defines how a system is introduced into the field. How it evolves once deployed. How it responds to change, failure, and risk. Without this layer, devices are static. They are programmed, deployed, and expected to operate indefinitely under conditions that will inevitably change.
In such systems, any form of evolution becomes difficult. Updates are manual or inconsistent. Visibility is partial. Control is limited. Over time, the gap between the system and its environment grows. This is why lifecycle management cannot be treated as an extension of functionality. It is the mechanism that enables functionality to persist.
In Edge AI systems, this becomes even more critical.
Models are not fixed. They are refined, retrained, and adapted based on new data and changing conditions. Without a structured way to deploy and manage these changes, the system cannot evolve. It remains bound to the assumptions made at the time of deployment.
Lifecycle management ensures that this is not the case.
It provides a structured way to introduce change — securely, consistently, and at scale. It allows systems to adapt without requiring physical intervention. It maintains trust in environments where direct control is limited. Finally, It defines whether a system can move beyond initial deployment into sustained operation.
Lifecycle management is not an operational concern — it is a foundational requirement.
The Lifecycle of an Edge Device¶
Edge devices do not exist in a single state.
They move through a sequence of stages — from creation to deployment, through operation and change, and eventually to retirement. Each stage introduces different requirements, risks, and expectations.
Understanding this lifecycle is essential. The challenges of Edge AI do not appear at a single point in time — they emerge across the entire lifespan of the system.
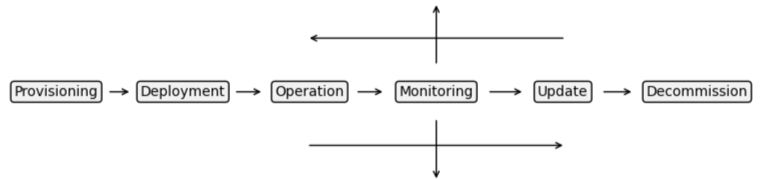
Figure 3: Lifecycle of an Edge Device
Provisioning¶
Every device begins with an identity.
Before it is deployed, it must be provisioned with credentials, keys, and the initial configuration required to operate within a system. This is the point at which trust is established. If identity and trust are not correctly defined here, everything that follows becomes uncertain.
Deployment¶
Once provisioned, the device is introduced into the field.
It is installed into an environment — an airport, a factory, a distributed infrastructure — where it begins operating under real conditions. At this point, direct access becomes limited. The device is no longer part of a controlled system. It is part of a distributed one.
Operation¶
During operation, the device performs its intended function.
It processes data, executes logic, and contributes to the larger system. This stage often receives the most attention during development, because it is where functionality is most visible. But the state of operation is not static.
Conditions change. Inputs vary. Systems interact in unexpected ways. A device that operates correctly at deployment must continue to operate correctly as its environment evolves.
Update and Evolution¶
Over time, change becomes necessary.
Models are refined. Logic is improved. Vulnerabilities are discovered. New requirements emerge. At this stage, the system must be able to evolve.
Updates must be delivered securely and consistently across devices. Changes must be applied without disrupting operation. The system must remain stable while adapting. Without this capability, the device becomes locked in time.
Failure and Recovery¶
No system operates without failure.
Devices may encounter errors, degraded performance, or unexpected conditions. Some failures are local. Others affect entire fleets. The ability to detect, diagnose, and respond to these failures is critical. Without visibility and control, failures persist longer than they should — and their impact grows.
Decommissioning¶
Eventually, devices reach the end of their lifecycle.
They may be replaced, repurposed, or removed from operation. At this point, identity must be revoked, access must be terminated, and any sensitive data must be handled appropriately. Without proper decommissioning, systems leave behind residual risk.
Each stage is part of the same system — they are not independent concerns.
A weakness in provisioning affects deployment, a limitation in updates affects long-term operation, a lack of visibility affects recovery.
The lifecycle is continuous — managing it requires more than isolated capabilities. It requires a system that spans the entire journey of the device — from its first introduction into the field to its final removal.
What's Actually Missing¶
The lifecycle of an Edge device is well understood.
Provisioning, deployment, operation, updates, recovery, and decommissioning are not new concepts. Each stage has been addressed in some form across different parts of the industry.
But they are rarely addressed as a whole. Instead, they exist as disconnected capabilities — implemented independently, managed separately, and often introduced only when problems begin to surface.
Identity may be handled during manufacturing or initial provisioning, updates may be implemented through custom mechanisms or vendor-specific tools, monitoring may rely on partial telemetry or external systems, and security may be addressed reactively, in response to vulnerabilities or incidents.
Each of these pieces may function — but they do not form a system.
There is no unified layer responsible for managing the lifecycle end-to-end.
As a result, responsibility is fragmented, different teams own different parts of the problem, different tools address different stages, and different assumptions are made at each layer.
The lifecycle exists — but it is not managed.
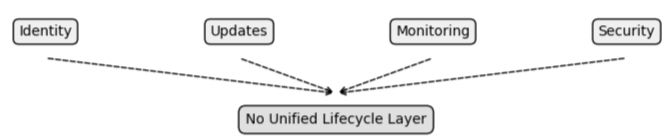
Figure 4: Fragmented Lifecycle Capabilities
This fragmentation introduces complexity.
Integrating these pieces requires additional effort, maintaining consistency across devices becomes difficult, and ensuring security across them becomes uncertain.
Over time, the system becomes harder to reason about. Not because any individual component is flawed, but because there is no cohesive structure connecting them.
This is where the gap persists. Even when all the necessary capabilities are present, the absence of a unifying layer means that they cannot operate effectively together. The result is a system that appears complete — but behaves unpredictably.
It can deploy. It can update. It can monitor. But it cannot do these things consistently, securely, and at scale — without that consistency, there is no real control.
Why Cloud Thinking Fails at the Edge¶
Much of modern software architecture has been shaped by the cloud.
Deployment pipelines, continuous updates, centralized monitoring, and automated recovery are well understood patterns. They have matured over years of iteration and are supported by robust infrastructure.
It is natural to assume that these same approaches can be extended to the edge. In principle, they can. In practice, they do not translate directly. The conditions at the edge are fundamentally different.
In cloud environments, systems are designed around constant connectivity. Resources are abundant. Control is centralized. Systems can be updated, monitored, and reconfigured in real time.
At the edge, none of these assumptions hold consistently. Devices may operate with intermittent or unreliable connectivity. Resources are constrained and tightly managed. Control is distributed across large numbers of devices. A device may be offline for extended periods. It may operate in environments where bandwidth is limited or expensive. It may not be reachable when updates are required.
This changes how lifecycle management must be designed.
In cloud systems, failure is often handled through redundancy and rapid replacement. Instances can be restarted, scaled, or redeployed with minimal impact.
At the edge, failure is persistent. A device that fails cannot simply be replaced. It must be diagnosed and recovered remotely — often under limited visibility and constrained conditions.
Similarly, updates in the cloud are continuous and immediate — at the edge, updates must be resilient. They must account for partial delivery, interrupted communication, and inconsistent device states. They must ensure that systems remain stable even when updates cannot be applied uniformly.
Security follows the same pattern. In centralized systems, access can be controlled and revoked in real time. In distributed edge environments, trust must be established and maintained even when direct control is limited.
These differences are not incremental — they change how systems must be designed. Attempting to apply cloud-native lifecycle patterns directly to edge systems leads to fragile solutions — systems that work under ideal conditions, but fail when those conditions are not met.
The problem is not that cloud approaches are wrong. It is that they assume a level of control that does not exist at the edge. Lifecycle management at the edge must be built around constraint, variability, and limited access. It must operate reliably in environments where control is not continuous, and where systems must remain functional even when they cannot be reached.
This requires a different approach.
Not an adaptation of cloud patterns — but a rethinking of how lifecycle management is implemented under fundamentally different conditions.
The Core Capabilities of Lifecycle Management¶
Lifecycle management is not a single function.
It is a set of capabilities that work together to maintain control over a system as it evolves over time. These capabilities are not independent features — they are interdependent elements of a larger structure.
When they are designed and implemented as a cohesive system, they enable devices to operate reliably, adapt to change, and remain secure throughout their lifecycle. At the edge, five capabilities define this system.
Identity and Trust¶
Every device must be uniquely identifiable.
Identity establishes the foundation for all interaction. It defines which devices are part of the system, how they are recognized, and how trust is established between components.
Without a strong identity model, there is no reliable way to control access, verify communication, or ensure that only authorized devices participate in the system. Trust begins here — and everything else depends on it.
Secure Communication¶
Devices must be able to communicate reliably and securely.
This includes not only protecting data in transit, but ensuring that communication channels cannot be intercepted, manipulated, or impersonated. At the edge, communication is often intermittent and constrained. Security mechanisms must operate within these limits while maintaining integrity and confidentiality.
Without secure communication, control cannot be enforced.
Remote Updates¶
Systems must be able to evolve after deployment.
This includes updating firmware, application logic, and AI models across a distributed fleet of devices. Updates must be delivered securely, applied consistently, and validated to ensure that systems remain stable. At the edge, updates cannot assume continuous connectivity or uniform device state. They must be resilient to interruption and capable of handling partial deployment scenarios.
Without reliable updates, systems become static — and over time, obsolete.
Observability¶
Systems must provide visibility into their behavior.
This includes telemetry, status reporting, and the ability to understand how devices are performing over time. Observability enables detection of anomalies, diagnosis of issues, and validation of system state. At the edge, visibility is inherently limited. Observability must be designed to operate within these constraints while still providing meaningful insight.
Without observability, failures remain hidden — and control becomes reactive.
Control and Orchestration¶
All of these capabilities must be coordinated.
Control is the ability to influence device behavior remotely — deploying changes, enforcing policies, and managing system state across a fleet.
Orchestration ensures that these actions are applied consistently, even when devices are distributed, intermittently connected, or operating under different conditions.
This is what transforms individual capabilities into a system. Without control and orchestration, the lifecycle remains fragmented — even if all other capabilities exist.
These capabilities are not optional.
They define whether a system can be managed over time. If any one of them is missing or incomplete, the system loses coherence: updates become unreliable, security becomes uncertain, and visibility becomes partial.
The system may still function — but it cannot be controlled.
From Capability to Control¶
The capabilities of lifecycle management — identity, communication, updates, observability, and orchestration — are often considered individually. They are implemented as features, and are evaluated as components — but their value does not lie in their existence, it lies in what they enable.
Taken together, these capabilities define a single outcome:
Control.
Control over how devices behave, how they change, and how they are trusted.
Without this control, systems are reactive — they respond to issues after they occur. They adapt slowly, inconsistently, or not at all. They depend on manual intervention in environments where manual access is limited.
With control, systems become manageable.
Changes can be introduced deliberately, behavior can be influenced remotely, and trust can be maintained continuously — not assumed. This distinction is critical.
Edge AI systems are not static — models evolve, conditions change, and requirements shift over time.
Without the ability to control this evolution, the system becomes fixed at the moment of deployment — unable to adapt, unable to improve, and increasingly misaligned with its environment.
Control ensures that this does not happen.
It allows systems to evolve in place — securely, consistently, and at scale. It provides a mechanism for responding to change without disrupting operation. It maintains continuity in environments where direct access is limited.
It defines whether a system can move beyond initial deployment into sustained, reliable operation. This is what lifecycle management ultimately provides — not just a set of capabilities — but the ability to control a system over time.
Without it, Edge AI systems can run — but they cannot be controlled.