Architectural Shift: Separation of Concerns¶
The Monolithic Assumption¶
A single device — a single microcontroller — should be responsible for everything.
- it reads sensor data,
- it executes application logic,
- it runs AI models,
- it manages connectivity,
- it implements security,
- it handles updates.
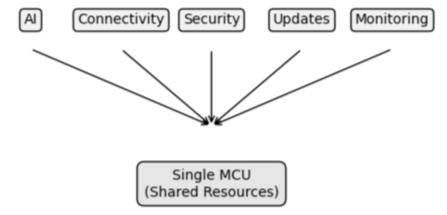
Figure 5: Monolithic Edge Design
At first glance, this seems efficient — all functionality is contained within a single system. There are fewer components to manage, fewer interfaces to define, and a clear, centralized point of control.
For prototypes, this works well. It allows developers to move quickly. Functionality can be demonstrated in isolation and the system is easy to reason about because everything exists in one place.
However, as systems move beyond prototypes, this simplicity begins to break down.
Each of these responsibilities introduces its own set of requirements.
- AI workloads demand processing and memory,
- connectivity requires protocol handling and network resilience,
- security introduces cryptographic operations and trust management,
- lifecycle management needs update mechanisms, observability, and control.
These concerns do not evolve at the same pace. They do not have the same constraints — and more importantly they do not fail in the same way. Yet in a monolithic design, they are forced to coexist within the same environment.
This creates tension — resources become contested, complexity increases, changes in one area begin to impact others in unpredictable ways, a modification to networking logic may affect system stability, a security update may introduce performance overhead, and an AI model update may push the system beyond its memory limits.
Over time, the system becomes harder to maintain. Not because any individual component is inherently complex — but because they are tightly coupled.
This coupling has another consequence — it expands the attack surface.
When connectivity, application logic, and system control all reside in the same environment, exposing one part of the system exposes all of it.
A vulnerability in networking code becomes a vulnerability in the entire device. In resource-constrained environments, this risk is amplified. There is limited ability to isolate processes, to enforce boundaries and to recover from failure.
Everything shares the same space — and everything shares the same risk.
This is the core limitation of monolithic edge design. It attempts to solve multiple independent problems within a single, constrained environment.
It works — until it doesn’t. When it fails, it fails as a whole.
When Everything Becomes Everyone’s Problem¶
Monolithic design does not only affect systems — it affects the people responsible for building and maintaining them. When multiple concerns are combined into a single environment, the boundaries between responsibilities begin to disappear.
What starts as a technical decision becomes an organizational challenge.
In a typical Edge system, different domains require different expertise: embedded engineers focus on hardware interaction and performance, AI teams focus on models, data, and inference, security specialists focus on trust, encryption, and threat mitigation, and connectivity experts focus on protocols, reliability, and data exchange.
Each area is complex in its own right — and requires a different way of thinking.
Each area evolves independently — in a monolithic system, these domains converge into a single implementation — the same environment must support all concerns, the same code base must accommodate all requirements, and the same device must satisfy all constraints.
As a result, responsibilities begin to overlap.
Developers working on application logic must consider security implications, teams focused on connectivity must account for resource limitations introduced by AI workloads, and security updates must be coordinated with system stability and performance constraints — no concern exists in isolation.
This creates friction, changes become harder to implement, dependencies increase, and testing becomes more complex. A modification in one area requires validation across all others. A failure in one component can cascade into the rest of the system — coordination becomes a bottleneck.
This leads to a familiar pattern — progress slows, systems become fragile, teams become cautious, and innovation is constrained — not by lack of capability, but by the risk of unintended consequences.
The underlying issue is not a lack of skill or expertise — it is a lack of separation.
When concerns are not clearly defined and isolated, ownership becomes blurred. Everyone is responsible for everything.
As a result, no one has full control over anything. This is where complexity begins to scale — not just within the system, but across the organization. Once it reaches this point, adding more features or capabilities does not solve the problem — it amplifies.
Separation of Concerns, Reintroduced for the Edge¶
The challenges outlined so far are not new. They emerge from a well-understood problem in system design — the accumulation of multiple responsibilities within a single environment, where independent concerns are forced to coexist under shared constraints. There is a principle designed to address exactly this.
Separation of concerns.
At its core, separation of concerns is the practice of dividing a system into distinct parts, where each part is responsible for a specific function and operates within clearly defined boundaries.
When applied effectively, this approach reduces complexity by allowing systems to be understood, developed, and maintained in manageable units. It also enables individual components to evolve independently, without introducing unintended consequences across the rest of the system.
This principle is widely used in software architecture. Applications are divided into layers, services are separated into independent components, and systems are decomposed into smaller, more focused units. These patterns are well established and have proven effective in managing complexity at scale.
At the edge, however, this principle is often applied only partially.
In many cases, separation exists within the software itself — tasks may be divided within a real-time operating system, and modules may be structured within a code base. While this introduces a degree of organization, it does not fundamentally change how the system behaves.
All components still share the same execution environment.
They rely on the same resources, operate under the same constraints, and ultimately fail together. From an operational perspective, they remain tightly coupled, even if they appear logically separated.
This is where the limitation becomes apparent.
Separation within a shared environment creates structure, but it does not create independence — it improves readability and maintainability at a code level, yet it does not address the deeper challenges of isolation, control, and resilience.
To address the realities of Edge AI and lifecycle management, separation must extend beyond software. It must become a property of the system itself.
The difference becomes clear when comparing logical separation to true isolation:
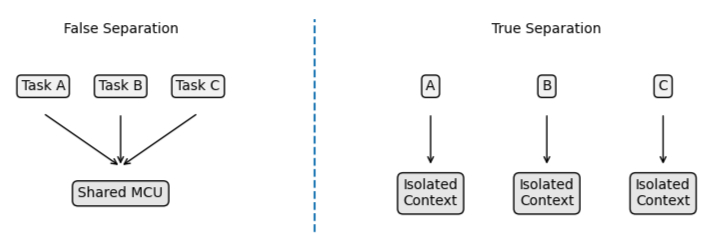
Figure 6: False vs True Separation
Structure improves organization — but independence is what enables control.
This requires defining boundaries not only in code, but in execution. Responsibilities must be isolated in such a way that they can operate, evolve, and be managed independently.
Changes in one concern should not directly impact the behavior or stability of another, and failures should be contained rather than propagated.
This is the distinction that matters.
Separation of concerns is not simply about organizing functionality — it is about controlling interaction between parts of a system.
Without this level of separation, complexity remains coupled. Failures spread across components, changes become increasingly risky, and control becomes difficult to maintain over time.
With it, systems become more predictable, more resilient, and ultimately more manageable as they evolve.
From Software Pattern to System Architecture¶
Separation of concerns is well established in software.
It has evolved into a set of architectural patterns that enable systems to scale in complexity without becoming unmanageable.
One of the most widely adopted approaches is the decomposition of applications into independent components — services, modules, or processes — that operate alongside each other while maintaining clear boundaries.
These patterns are not only about organization; they are about isolation.
In modern systems, this often takes the form of loosely coupled services that communicate through well-defined interfaces.
Each component can be developed, deployed, and updated independently, without requiring changes to the entire system. This approach allows complexity to be distributed rather than concentrated, reducing the risk of cascading failures and enabling continuous evolution.
One particularly relevant concept is the idea of a “sidecar.”
In this model, supporting functionality is not embedded directly within the primary application. Instead, it exists as a parallel component — running independently, but closely coupled in purpose.
The sidecar provides additional capabilities such as communication, security, or monitoring, without increasing the complexity of the core application itself.
This approach introduces a powerful idea.
Functionality can be extended without being entangled. At the edge, however, these patterns are difficult to apply directly. The constraints of resource-limited devices, the absence of traditional process isolation, and the lack of supporting infrastructure make it challenging to replicate cloud-native architectural models.
As a result, many Edge systems continue to rely on monolithic designs — not because they are ideal, but because the alternatives appear impractical.
This is where a fundamental shift in perspective is required.
Instead of attempting to replicate software-level separation within a single execution environment, the principle must be elevated to the system level. Separation must be achieved not only through logical boundaries, but through independent execution contexts. This introduces a different way of thinking about system design.
Rather than asking how multiple concerns can coexist within the same environment, the question becomes:
How can they be separated in a way that preserves independence while still enabling collaboration?
In this model, components do not simply share resources — they interact through controlled interfaces, they do not compete for execution — they operate in parallel. They do not fail together — they are isolated by design. This is the foundation for a new class of Edge architecture.
One in which responsibilities are not just divided, but decoupled at a structural level.
One in which complexity is managed not by adding layers within a single system, but by distributing concerns across independently controlled environments.
This shift does not eliminate complexity. It changes where that complexity lives — and how it is managed.
The Concept of Disconnection¶
Connectivity is often seen as the defining characteristic of modern systems.
The ability to connect devices, exchange data, and interact with systems in real time has enabled much of the progress associated with the Internet of Things — it has expanded what devices can do, how they are managed, and how value is created from distributed environments.
Connection makes these systems possible — exposure makes them vulnerable.
Every interface that is opened, every service that is exposed, and every pathway that allows interaction with a device becomes a potential point of vulnerability. As systems become more connected, they also become more accessible — not only to intended participants, but to unintended ones as well.
This is not a flaw in implementation. It is a consequence of design.
The industry has largely accepted this trade-off. Devices are connected to enable functionality, and security is applied to mitigate the risks introduced by that connectivity. Layers of protection are added — encryption, authentication, firewalls, intrusion detection — in an effort to reduce the likelihood and impact of compromise.
These measures are necessary.
However, they do not change the underlying reality. A connected system remains exposed by design. This leads to a different way of thinking. Instead of asking how to secure everything that is connected, it becomes possible to ask a different question:
What if not everything needs to be connected in the first place?
Disconnection, in this context, does not mean the absence of communication. It means the intentional limitation of exposure. It is the idea that certain parts of a system can remain isolated from external networks, while still participating in the overall behavior of the system through controlled interaction points.
This is a subtle but important distinction.
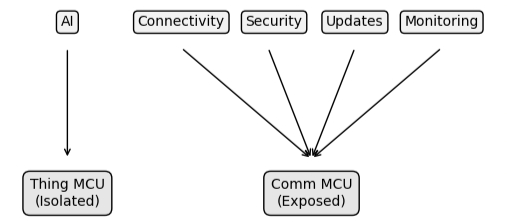
Figure 7: Separated Edge Architecture
A system can be connected as a whole, while individual components remain unreachable from the outside. Communication still occurs — but it occurs through defined, controlled pathways rather than direct exposure. In practical terms, this reduces the attack surface.
Components that do not need to be externally accessible are not exposed. Services that do not require inbound connectivity are not reachable. The number of entry points into the system is minimized — not through filtering, but through design.
This approach aligns with a simple observation:
The fewer ways there are to interact with a system, the fewer opportunities there are to compromise it.
Disconnection, therefore, is not about limiting functionality. It is about redefining how that functionality is accessed. When applied as an architectural principle, it allows systems to retain the benefits of connectivity — data exchange, remote control, lifecycle management — while reducing the risks associated with direct exposure.
It creates a boundary — what must be reachable and what should remain isolated.
This boundary becomes a powerful tool. It enables separation not just in responsibility, but in visibility. It allows certain parts of the system to operate without being directly influenced by external conditions, while still contributing to the overall system behavior.
In this sense, disconnection is not the opposite of connection. It is the mechanism that makes controlled connection possible. This defines a model of controlled disconnection at the edge.
Toward a New Edge Architecture¶
The principles outlined so far — separation of concerns and controlled disconnection — point toward a different way of designing Edge systems. Not as a single, unified environment responsible for everything, but as a collection of distinct components, each with a clearly defined role.
In this model, responsibilities are no longer combined within a single execution context. Instead, they are distributed. Application logic, AI processing, connectivity, security, and lifecycle management are treated as separate concerns — not only in theory, but in how they are implemented and executed. Each operates within its own boundary.
This shift changes how systems behave.
Components no longer compete for the same resources in the same way. They do not evolve at the same pace, and they are no longer forced to, and changes can be introduced in one part of the system without requiring synchronized changes across all others. The system becomes more adaptable — not because it is simpler, but because it is structured.
It also changes how systems fail. In tightly coupled designs, failures tend to propagate. A fault in one area can affect the entire system, leading to unpredictable behavior and difficult recovery. In a separated architecture, failures can be contained. A problem in one component does not necessarily compromise the others.
Boundaries act as safeguards, limiting the scope of impact and preserving overall system stability. This separation also introduces a clearer model for control.
When responsibilities are isolated, they can be managed independently. Communication pathways can be defined explicitly, rather than assumed implicitly.
Trust relationships can be established at the boundaries between components, rather than across an entire system. Control becomes more precise. Importantly, this approach does not remove the need for connectivity — it refines it.
Instead of exposing all components to the same network conditions, connectivity can be centralized and controlled. External interaction can be limited to specific parts of the system, while others remain isolated and protected by design.
The system remains connected — but not uniformly exposed. This is the architectural shift. At this point, a practical question naturally emerges.
Reusing Existing Capabilities¶
One immediate concern with this architectural approach is that it appears to introduce additional complexity. Separating responsibilities across multiple execution contexts suggests the need for additional hardware, additional integration effort, and a more complex system design.
At first glance, this seems at odds with the constraints of Edge systems. In practice, however, this separation does not necessarily require introducing new components.
Many modern Edge deployments already rely on communication modules to provide connectivity. These modules are responsible for handling protocols, managing network interaction, and maintaining communication with external systems.
Increasingly, these modules also provide programmable environments.
A growing number of communication modules support what is often referred to as an “OpenCPU” model. In this approach, the module itself exposes an execution environment that allows developers to run custom logic directly within the communication layer. This enables additional functionality to be implemented without requiring a separate physical component.
This capability creates an opportunity.
Rather than introducing a new microcontroller, the communication module can serve as the execution environment for connectivity, security, and lifecycle-related concerns. The primary device can remain focused on application logic and AI processing, while the communication module manages external interaction.
From an architectural perspective, the separation remains the same. Responsibilities are still divided. Execution contexts are still independent. Interaction is still controlled. But the implementation becomes more practical.
This approach aligns with the constraints of real-world deployments. It reduces the need for additional hardware. It leverages components that are already part of the system. It enables separation without significantly increasing complexity.
The result is an architecture that is both structured and achievable. It preserves the benefits of separation and controlled interaction, while remaining compatible with existing design patterns and hardware choices.
From monolithic systems to distributed responsibilities. From implicit interaction to controlled interfaces. From shared environments to isolated execution contexts. It is not a matter of adding new capabilities. It is a matter of designing systems in a way that allows those capabilities to function effectively over time.
This shift is what makes lifecycle management practical at the edge. Without it, the capabilities defined earlier remain constrained by the limitations of the underlying architecture. With it, they can operate as intended — independently, reliably, and at scale.
Lifecycle management is not enabled by architecture — it is defined by it. Without the right architecture, lifecycle management remains theoretical. With it, it becomes operational.